Ploto 周刊(第 8 期):RAG 的落地难点
本周刊主要记录我近期发现的 AI、科技、独立产品相关内容,以及我的一些思考。当然周刊的内容并不局限于这些,我也会记录下让我有感触的文章。欢迎感兴趣的朋友关注,便于获取更新通知。
文章
RAG在企业应用中落地的难点与创新
我这里只简单概括了 RAG 落地难点,文章里面其实还提到了几个实际的客户应用场景,比如金融研报辅助分析,零售商品导购助手、合同/项目规则预审批这几个场景,每个场景单独拿出来都可以作为一个细分产品,也值得阅读。
难点 1:文件解析
RAG 流程的第一步是各种复杂文件的解析,比较复杂的包括:
- “.doc” 这类老文件,同类产品一般只支持到 “.docx”,但大部分企业文档都有 “.doc” 文件,而且无法通过手工转 “.docx” 解决。
- 各类有数字签名、带图片的 PDF 解析。主要在于 PDF 扫描件、表格解析、图文布局问题,需要借助 OCR、布局识别。
最近恰好看到一个开源项目 gptpdf,解析 PDF 中所有非文本区域,然后通过视觉大模型(例如 GPT-4o)进行解析,得到一个 markdown 文件。不过视觉模型耗费比较大,平均下来每一页解析成本 $0.013。
难点 2:结构化数据
大部分情况下都需要对接企业原有的关系数据库或者 Excel 文件,也就是结构化数据,如果直接将数据 embedding 经常效果不佳,比如丢数据,而且无法处理时序数据。
如果直接进行 Text2SQL 的查询,在一些简单场景下都是没问题的,而一旦查询逻辑较为复杂,就出不了好的结果,或者很不稳定。
TorchV 最终采用了一种中间方案,把数据库的元数据抽出来,包括字段信息和表、视图的描述,人工补充一些必要的资源描述,再进行embedding。同时建立可重复使用的通用 data-func,可以把复杂 SQL 逻辑写进去,通过 function-call 做处理和转发,配合 LLM 理解用户意图,寻找相应的元数据和 data-func,进行一个或多个步骤的 SQL 组装,进行查询执行。
这种折中的方式在 data-func 的创建中会有一点工作量,但是执行效果比较稳定。
难点 3:索引过程中的其他工作
在初期验证环节,硬件条件不够的情况下,只能部署 6B、13B 和 14B 这样的模型,需要依靠更精准的检索能力,以便输出给大模型更纯净的内容。依赖元数据的处理,从文件的标题、目录、属性等内容中获取,包括文件名、年份月份等时间信息、组织和部门,以及财务、人事、销售、财务报表等关键标签。在文件处理的时候被自动抽出来进行管理,和 chunks 和索引做一对多的关联。
在检索时,首先使用一个规模比较小的基于 BERT 训练的幂等分类器进行 NER,然后使用识别的内容先在元数据里面进行查询,将索引范围进行限定,后面就是混合检索和 rerank 等操作。好处是可以将一些很相似的内容区分开,比如真实客户环境下,很多文件只有日期、部门和金额等内容是不同的,如果直接做检索,很可能因为切片时候错过这些关键信息而混杂在一起。
难点 4:检索中 rerank 的难点和解决
rerank 常用的方式就是将第一次检索的结果进行更准确的验证,通过交叉编码验证让召回的结果再进行排序,达到更精确的回答。TorchV 在 rerank 的结果中使用密度函数再做一个验证,如果得分突然掉下来了,那么就进行舍弃,好处是在结果的选择策略上做到宁缺毋滥。
在检索结果的原文显示上,通过 rerank 用答案和多个引用的原文再进行比较,找到最精确的原文来进行展示。
我做了一个 AI 搜索引擎
分享的非常详细,强烈推荐阅读原文,我这里仅列一下 ThinkAny 的时间线和一些具体数据
- 2024 年 3 月份,花一个周末使用 NextJs、serper.dev、gpt-3.5-turbo、daisyUI 完成 MVP
- 03/20 在 ProductHunt 发布 ThinkAny,在微信朋友圈 / 即刻 / Twitter 等地方发动态号召投票,冲到 ProductHunt 日榜第四,并接下来几天,Twitter / Youtube 等平台有用户自发传播
- 3 个月内累计用户 170k,日均 UV 3k,日均 PV 20k,日均搜索 6000 次;主要用户分布在埃及 / 日本 / 印度 / 美国 / 中国和其他中东地区
- 网站月访问量 580k(基于 similarweb 数据估算),5 月实际访问量较 4 月份增长 90%
- 5 月份发布的第二个大版本,上线了用户增值付费功能,然而支付率比较低,仅为 0.03% 左右
- ThinkAny 还开源了一个 API 项目:rag-search,完整实现了联网检索功能,并对检索结果进行重排(Reranking)/ 获取详情内容(Read Content)
How I Launched My First AI SaaS Yesterday
作者 Eddy Vinck 做了一个 Blog Recorder,MVP 版本功能是语音记录用户想法,然后通过 AI 将想法转换成一篇结构化的博客。Eddy 一开始选择 Build In Public,收集到了 200+ 的 waitlist 用户,产品初期就让朋友和部分有兴趣的用户进行内测。
Eddy 为了 Launch day 所做的准备:
- 每天早上定时发一篇 LinkedIn post
- 准备好了在 Twitter 上要发布的图片和文案
- 给所有 waitlist 用户准备了一封 launch 邮件
- 提前找了一些朋友沟通,帮忙转发、点赞、回复 Twitter launch 文案
- 在 Stripe 上创建折扣码,放在所有 pricing 页面以及网站 OG 图上
- 在下午 7 点发布 Tweet,并给用户发送 DM,回复帖子
- 调整 launch 邮件内容,发送给用户
- 在 Threads 上发布
Launch 结果:
- 21 新用户
- 1 个年付费用户
- 7 篇新用户记录的文章
独立产品
BizPlanner AI
利用 AI 生成商业计划,填写商业类型,目标人群,产品描述,竞争对手以及预算,然后由 AI 生成一份完整的商业计划书。生成的计划书仍然可以结合 AI 进行二次编辑,最终导出一份文档。
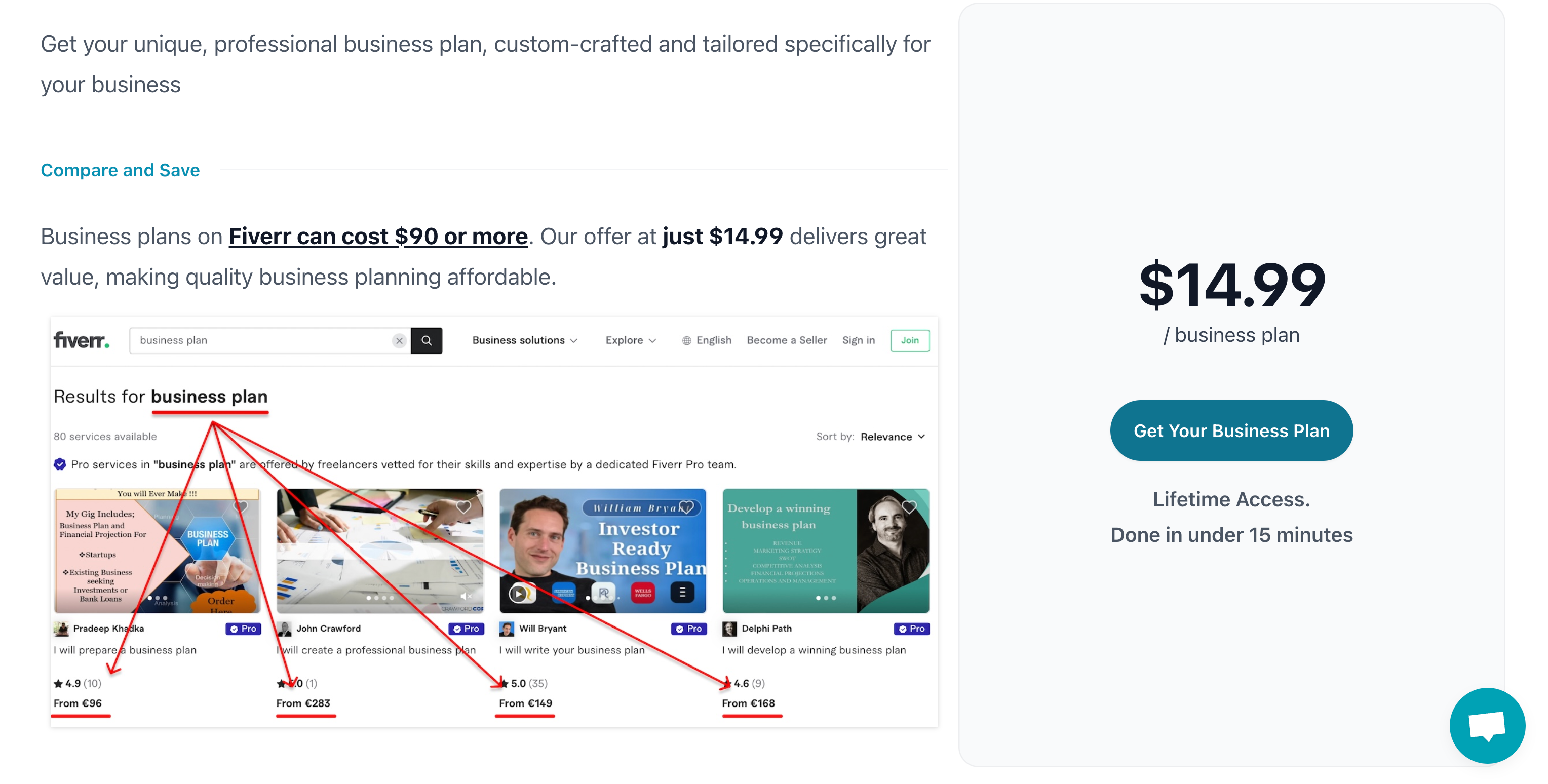
每个商业计划的价格是 $14.99,值得一提的是它的价格锚点是 Fiverr 上的 business plan,直接用市场价格凸显自己服务的价格优势。从另一个角度,Fiverr 也是一个需求宝库,可以直接根据 Fiveer 上的用户提供的服务来作为自己的 Idea。
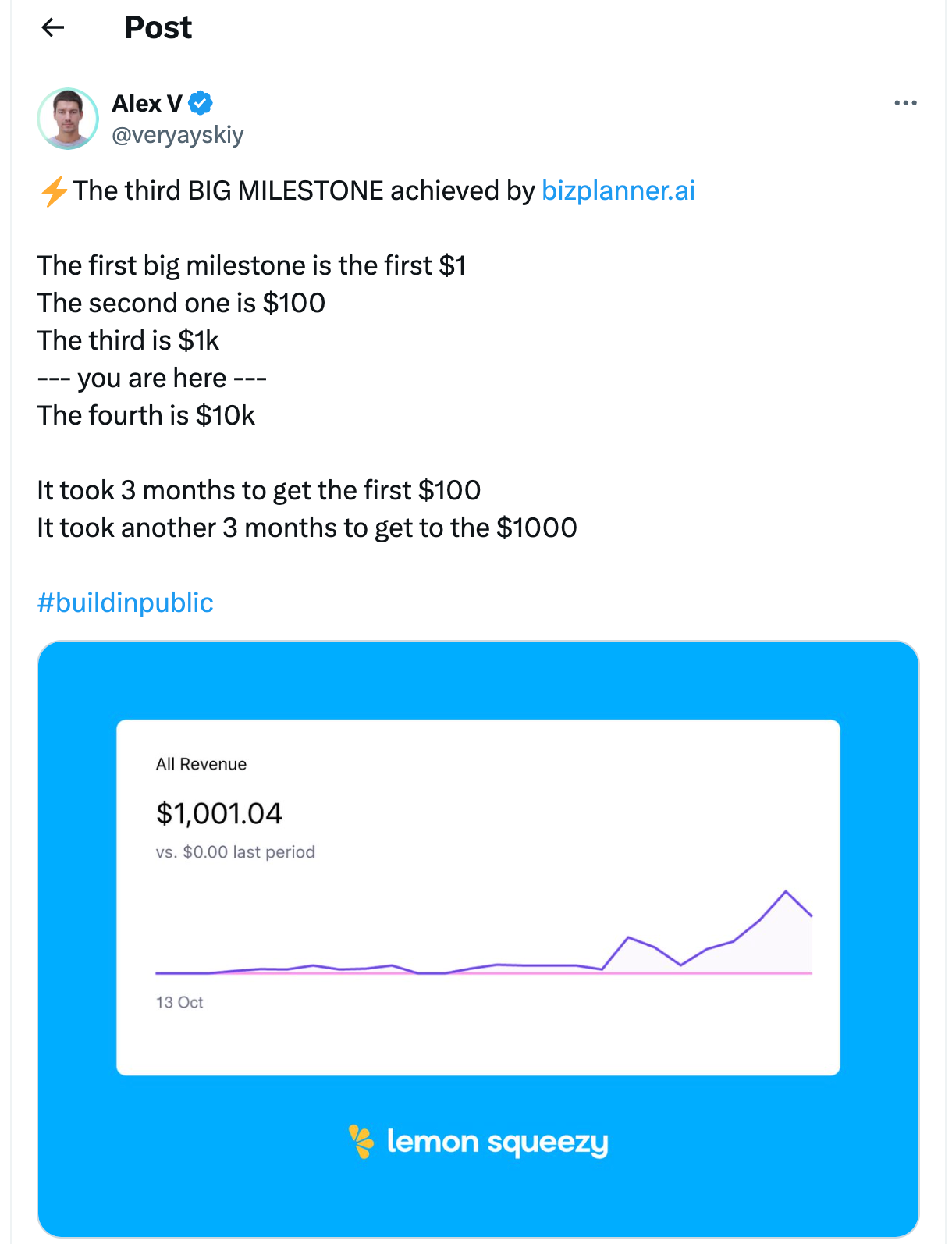
BizPlanner AI 花了 3 个月达到 $100 MRR,又在接下来的 3 个月内达到 $1000 MRR。
Famewall
一个 testimonials(用户评价)工具,可以比较方便的将各个平台上的用户好评导入进来并进行管理、排版展示,提高新用户对网站的信任度。
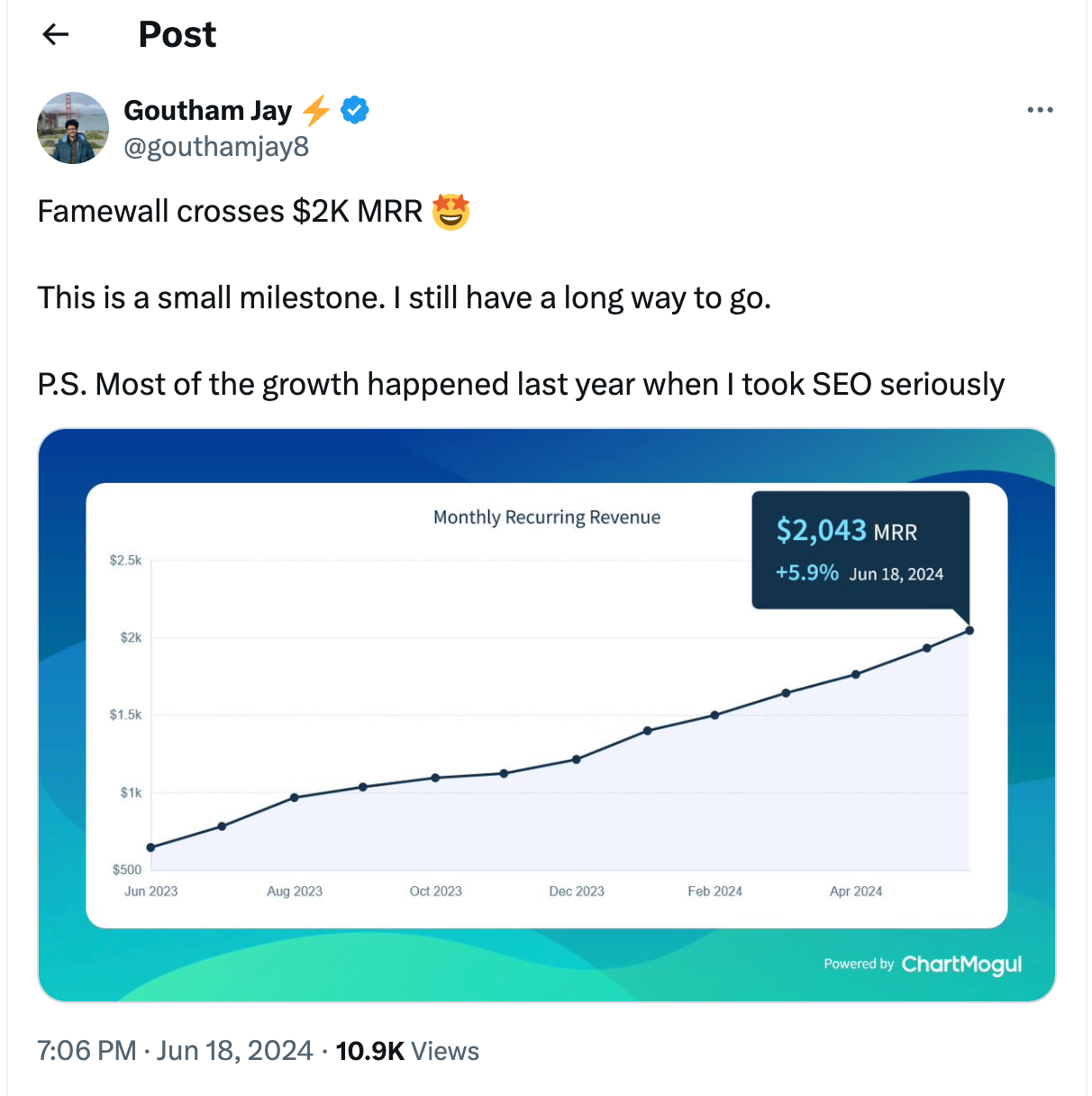
Famewall 在 6 月份达到了 $2k MRR,主要增长来源是 SEO
开源产品
gptpdf
使用视觉大语言模型(如 GPT-4o)将 PDF 解析为 markdown。可以比较完美地解析排版、数学公式、表格、图片、图表等。平均每页成本是 $0.013
另外还有个基于gpdpdf 的 WebUI 项目 gptpdf ui
WiseFlow
信息挖掘工具,可以从网站、微信公众号、社交平台等各种信息源中按设定的关注点提炼讯息,自动做标签归类并上传数据库,支持本地 LLM 模型。
WiseFlow 还改写了通用网页内容解析器,综合使用统计学习(依赖开源项目GNE)和LLM,适配 90% 以上的新闻页面。
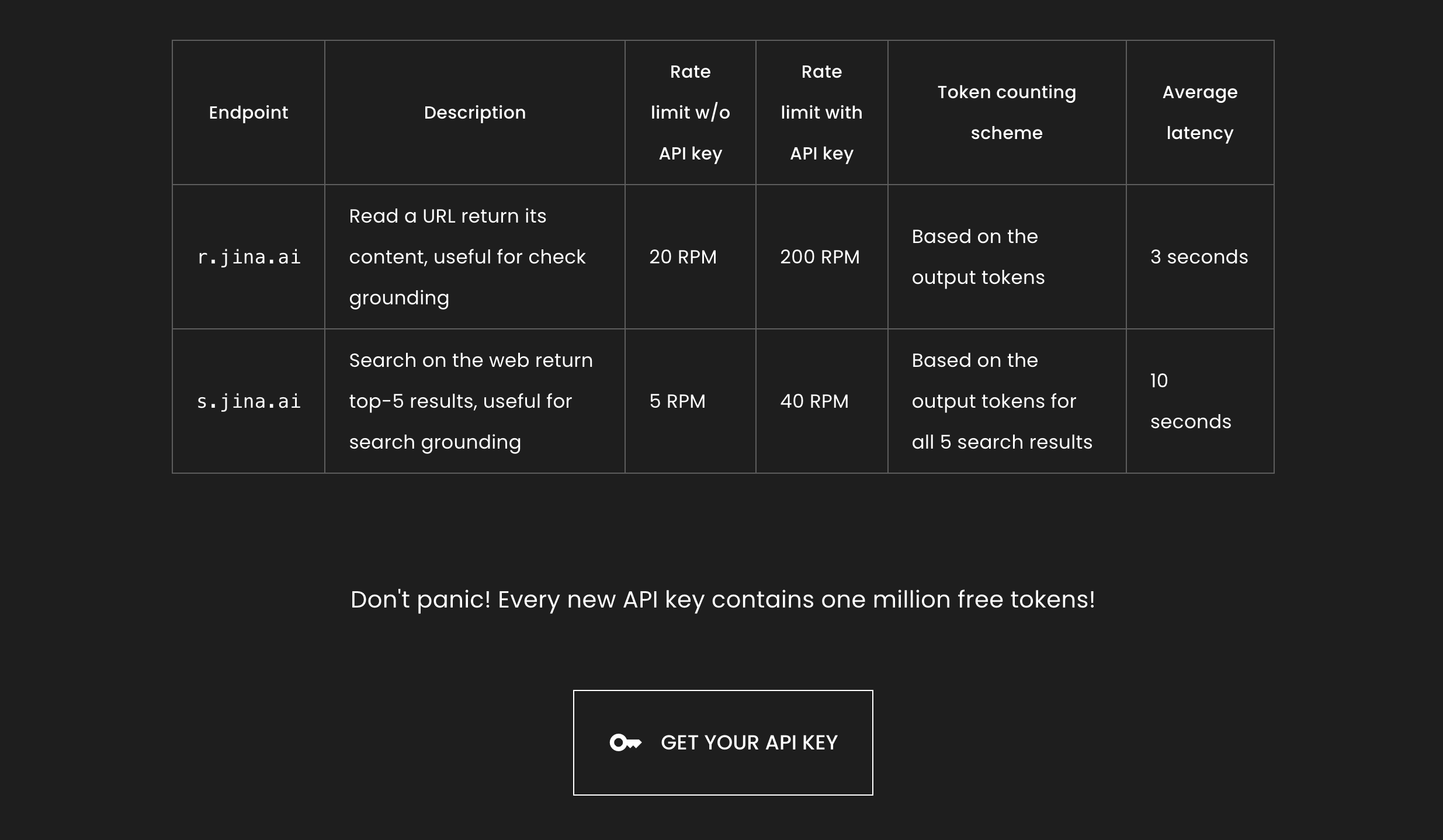
Jina AI Reader
- 能够将任意 url 转换成 LLM 友好的内容,用于后续 RAG 处理。
- 可以进行 query 搜索,从互联网获取最新数据。
Jina AI 提供了免费的接口,免费用户最高 20 RPM,新用户免费额度为 1M token。